技嘉RTX 4090 GAMING OC魔鹰显卡评测
2022-10-12 21:00
|
发布者:
橙黄鼠标|
查看:
19066|
评论:
|原作者: 橙黄鼠标
摘要:
Ada Lovelace架构
RTX 40系列显卡核心架构全称“Ada Lovelace”(以下简称Ada),采用台积电4N工艺制程制造。得益于先进的工艺制程,AD102完整核心塞进了763亿个晶体管,是上代GA102的2.7倍。核心面积反而从628平方 ...
第三代RT Cores光追核心


在Ada架构中,英伟达的光追核心已经升级到第三代。在原本的BVH包围盒碰撞(Box Intersection Engine)和三角形相交(Triangle Intersection Engine)的基础上增加了不透明微遮盖(Opacity Micromap Engine)以及微网格位移(Displaced Micro-Mesh Engine)两个全新引擎。
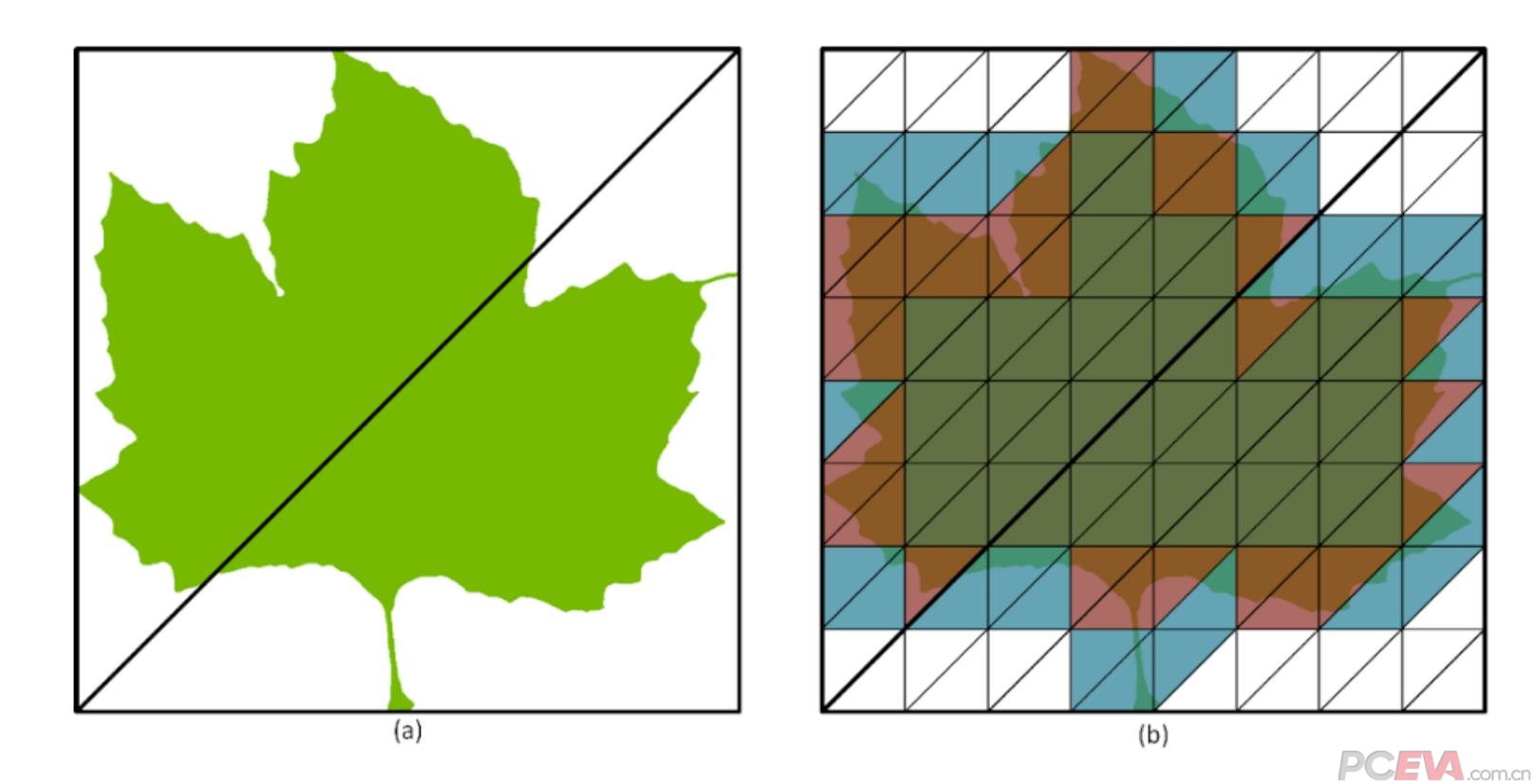
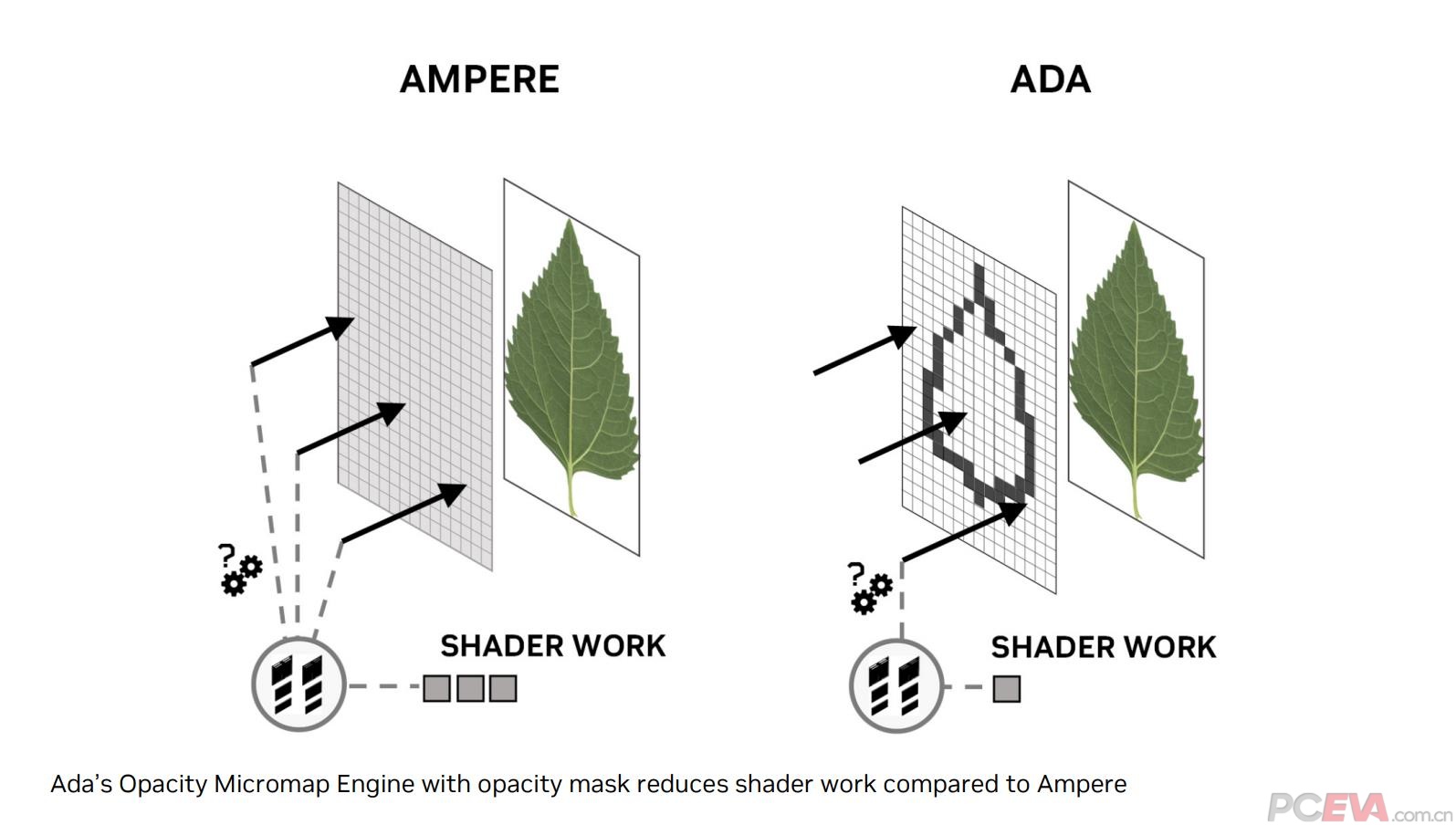
英伟达新增的两个引擎目的是相同的,都是为了降低BVH的使用工作量和创建时间。不透明微遮盖(OMM)引擎可以评估一个物体的光线相交穿透程度,并将其分类为不透明、透明、以及未知的不透明程度,并将其生成不透明微网格返回给着色器,以减少着色器的工作量。以图中的树叶为例,树叶的中心部分是不透明的,树叶的边缘则是有不透明程度,而外围则是完全透明。第二代的RT Core需要进行一遍完整的三角形遍历操作,而第三代只需要按照透明度进行部分BVH相交,大幅度提高了光线追踪的工作效率。
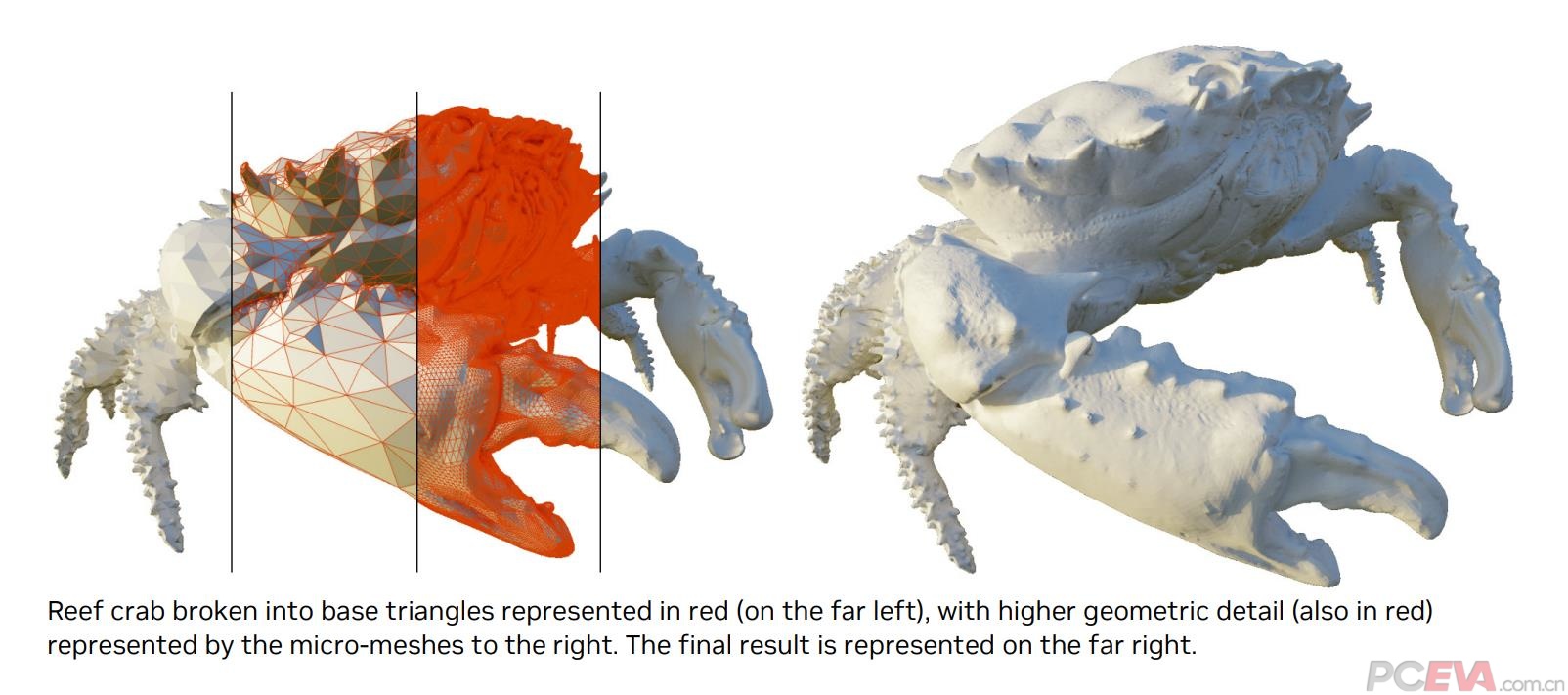

微网格位移(DMM)简单说就是以1个基础的三角形通过位移、旋转、缩小、放大等一系列操作生成更多复杂的几何图形,降低BVH的工作量和创建时间。

根据英伟达公布的数据,通过微网格位移(DMM)创建一个11:1的3D饰品盒,需要15.3万个微网格、1100万个微三角形,BVH速度可以加快8.5倍,使用的显存容量可以降低6.5倍;创建一个28:1的铜鼎,需要17.5万分微网格、5700万个微三角形,BVH速度可以加快15倍,使用的显存降低20倍;创建一个14:1的珍珠蟹,需要1.7万个微网格、160万个微三角形,BVH速度可以提高7.6倍,使用的显存降低8.1倍。
|

