技嘉RTX 4090 GAMING OC魔鹰显卡评测
2022-10-12 21:00
|
发布者:
橙黄鼠标|
查看:
18926|
评论:
|原作者: 橙黄鼠标
摘要:
Ada Lovelace架构
RTX 40系列显卡核心架构全称“Ada Lovelace”(以下简称Ada),采用台积电4N工艺制程制造。得益于先进的工艺制程,AD102完整核心塞进了763亿个晶体管,是上代GA102的2.7倍。核心面积反而从628平方 ...
Ada Lovelace架构
RTX 40系列显卡核心架构全称“Ada Lovelace”(以下简称Ada),采用台积电4N工艺制程制造。得益于先进的工艺制程,AD102完整核心塞进了763亿个晶体管,是上代GA102的2.7倍。核心面积反而从628平方毫米降低至608平方毫米,晶体管密度同样是上代的2.7倍。
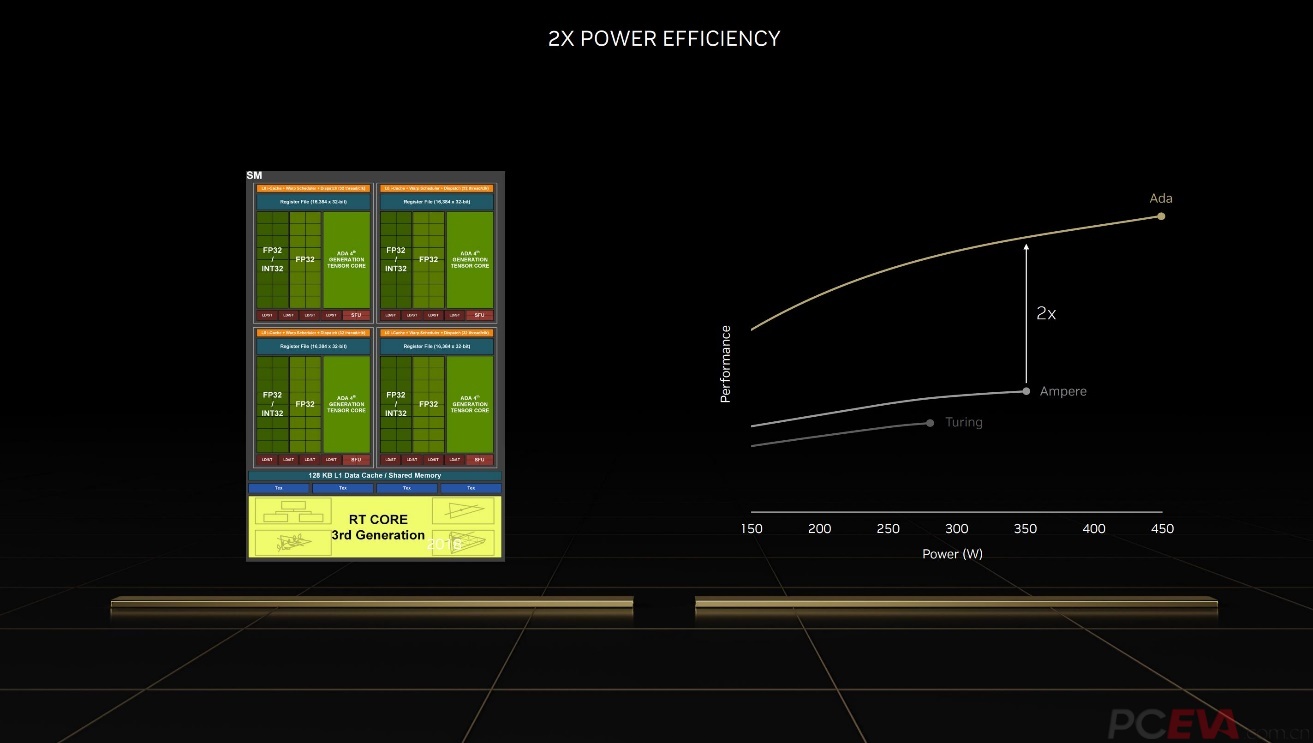
AD102在晶体管数量达到上代核心2.7倍的前提下,功耗表现依然维持了相同水准,标准功耗为450W,与RTX 3090 Ti相同。能耗比可达到GA102的2倍。
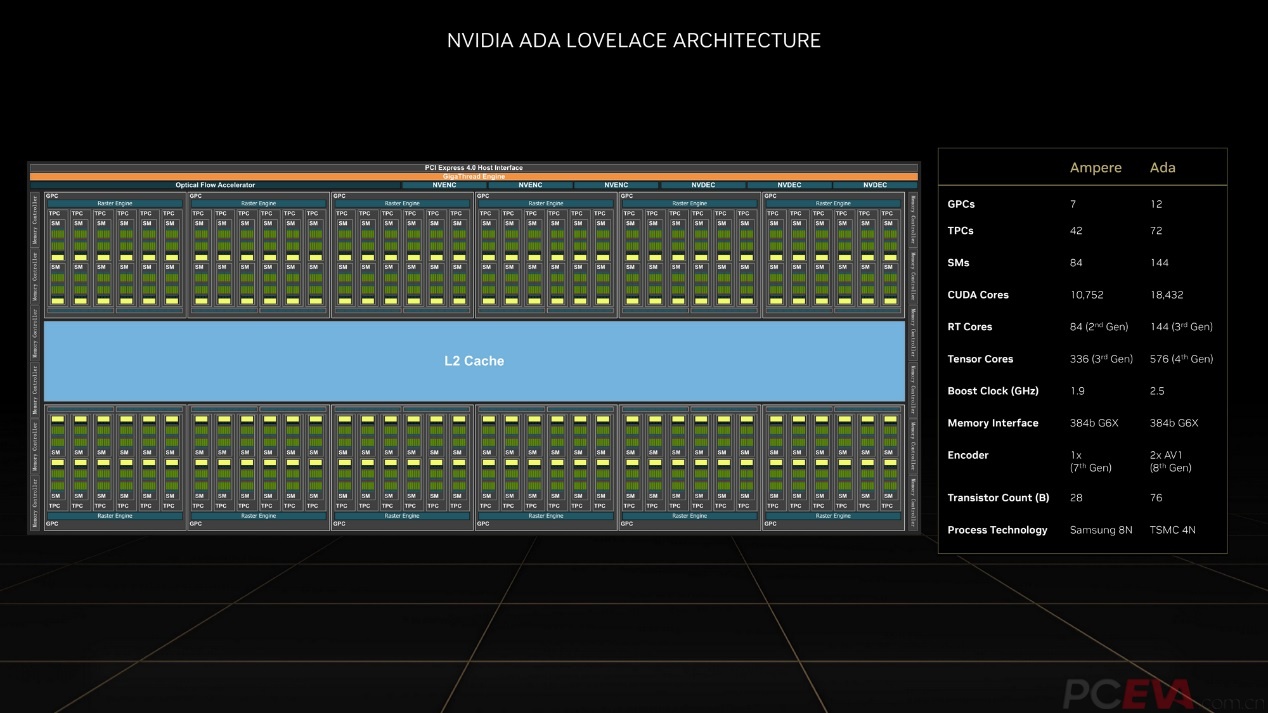
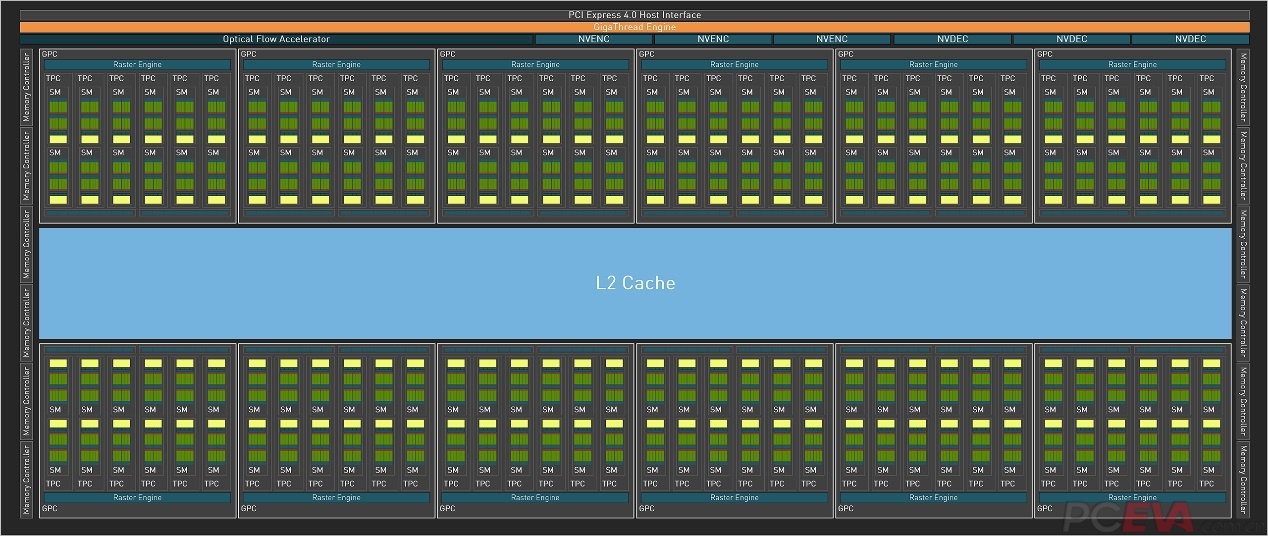
完整的AD102核心拥有12组GPC计算单元,每组GPC单元包含6组TPC计算单元,共计72组。每组TPC计算单元中又包含了2组SM流处理器单元,共计144组。每组SM流处理器单元中配备128个CUDA核心,共计18432个CUDA核心,是上代GA102的1.7倍。除了CUDA核心,AD102同时还配备了144个第三代RT Cores光追核心、576个第四代Tensor Cores张量核心,同样是上代的1.7倍。显存还是384-bit的24GB GDDR6X显存,等效带宽21Gbps,显存带宽可达1TB/s,和RTX 3090 Ti相同。
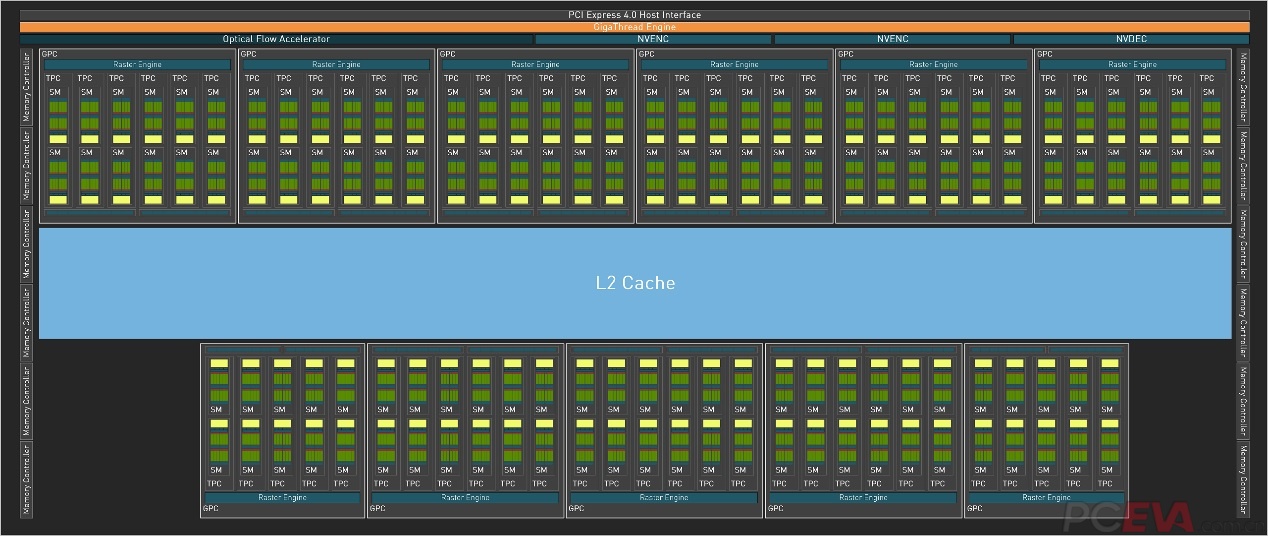
RTX 4090采用的不是完整AD102核心,而是屏蔽了1组GPC计算单元+4组SM流处理器单元(2组TPC计算单元)。RTX 4090最终的规格是128组SM流处理器单元,共计16384个CUDA核心,128个光追核心、512个张量核心,大约是上代RTX 3090 Ti的1.5倍规格。

Ada架构里每个GPC计算单元里包含1个专用光栅引擎、2个ROPs光栅分区,每个光栅分区又包含了8个ROPs光栅单元,另外还有6组TPC计算单元,每组TPC计算单元包含了1个多边形引擎和2个SM单元。
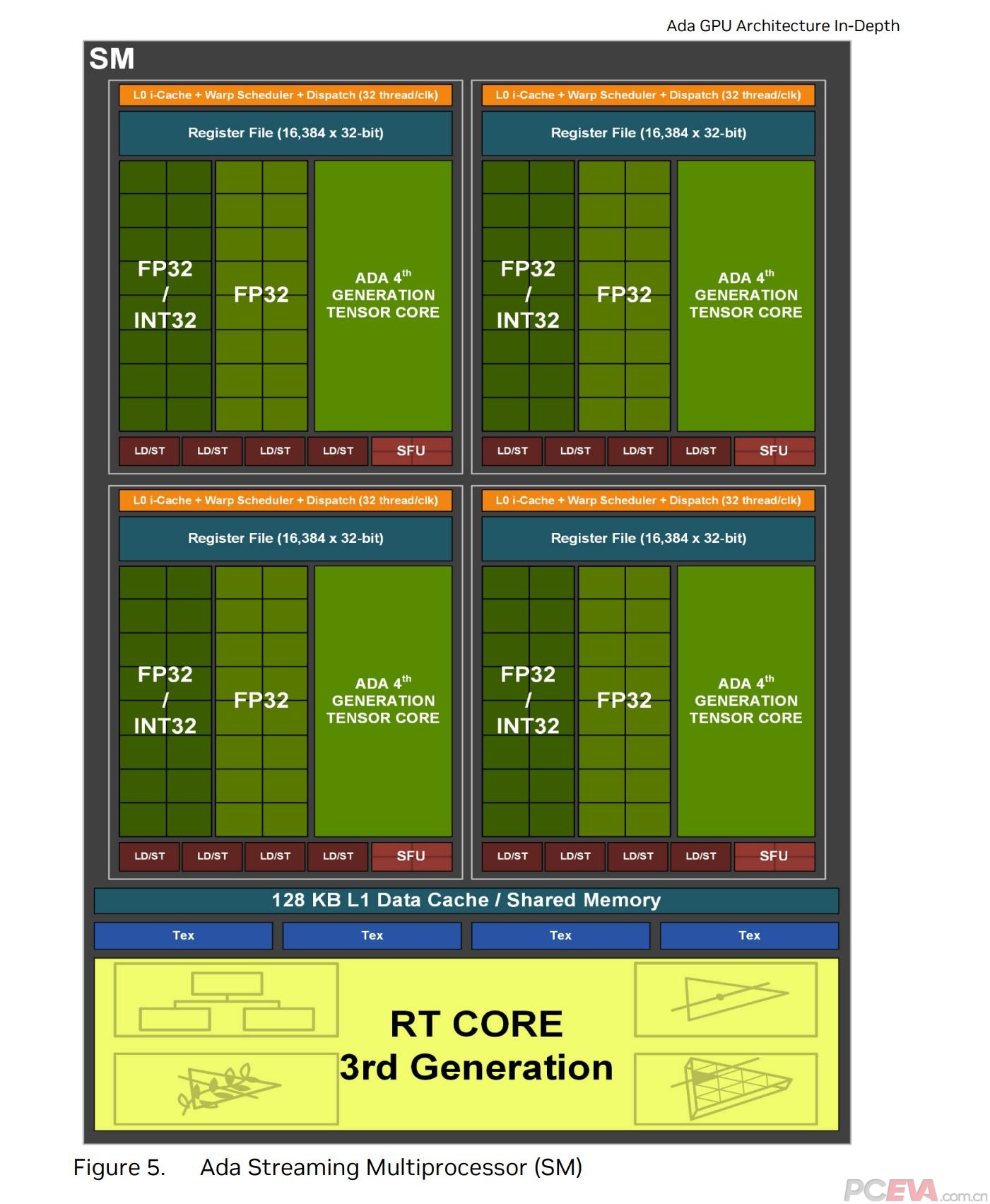
Ada架构的SM单元结构和上代基本没什么区别,每个SM单元有128KB L1一级缓存/共享缓存、4个纹理单元、1个第三代RT Core光追单元以及4个分区模块,每个模块又包含32个CUDA单元、1个第四代Tensor Core张量核心、4个存载单元、1个SFU特殊单元以及L0指令缓存、调度器+发射单元和64KB的寄存器文件。CUDA核心的设计和上代相同,每个模块里有一半(16个)是FP32浮点单元,负载单精度浮点运算;另外一半则是FP32/INT32浮点和整数动态切换运算。另外Ada架构每个SM单元包含2个FP64双精度浮点单元,但在消费级的架构示意图中并未标示,完整核心拥有总计288个双精度浮点单元。
|

