- 内容展现
- 最新评论
AMD Ryzen ThreadRipper 1950X与技嘉X399 AORUS Gaming 7评测
今天,AMD推出了Ryzen ThreadRipper处理器,意为“线程撕裂者”,同样基于Ryzen架构,多达16个核心,直接参与高性能PC市场的竞争,如此一来,多年未见的IA大战将波及整个PC产品线,而且,这次掀起的是“核战争”! . ...
基准测试
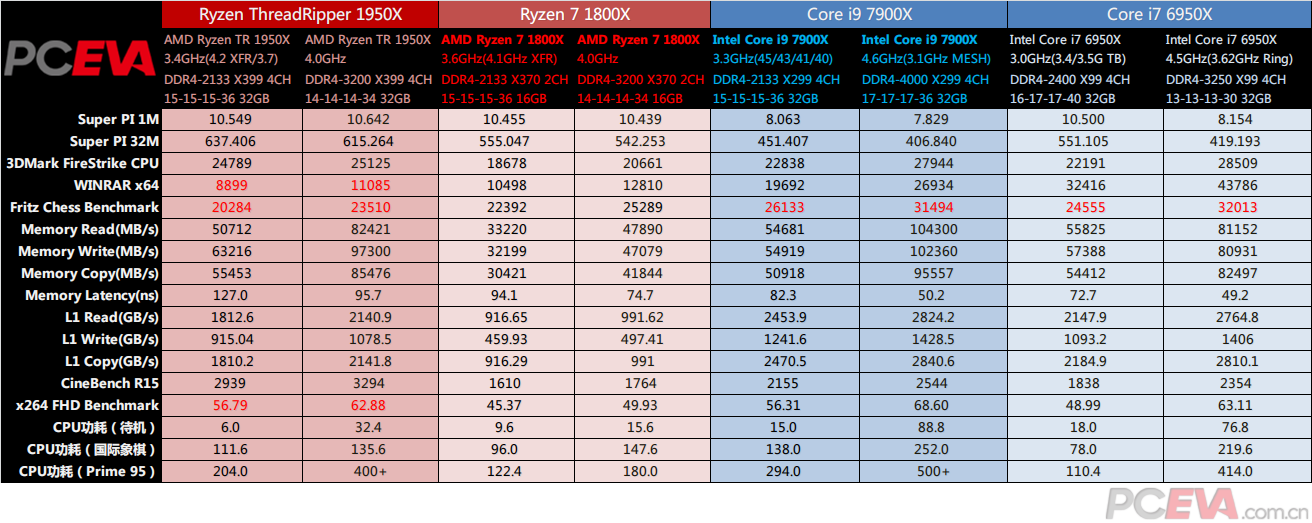
由于Intel这边超过10核心的Core i9还未上市,我们加入Ryzen 7 1800X、Core i7 7900X、Core i7 6950X来与TR 1950X对比。测试时我们把Windows电源管理设为高性能模式,以减少Ryzen处理器的性能损失。
内存性能方面,写入表现很出色,基本上达到Ryzen 7的两倍,也比Intel平台在DDR4-2133时更加快,而读取则稍微差一些,延迟就和AMD自己说的一样,果然很大。 功耗方面,默认状态下TR 1950X的功耗表现非常好,待机功耗在个位数,即使是跑Prime 95 29.1时也在204W的输入功率,刨去供电的损耗,180W的TDP看来卡得很死,而在跑渲染时大概在160W左右,整机功耗方面,待机大约在80W,满载不会超过280W。但是超频之后,功耗就不那么理想了,在1.38V 4G时,Prime 95的功耗已经超过400W,主板出现断电现象,即使是跑渲染也跑到370W,比默认状态下翻了一倍还多。考虑到超频空间有限,性能提升也非常有限,以及手动修改倍频后XFR会失效,我们不建议使用TR处理器超频使用。 |
本文版权归 PCEVA,PC绝对领域,探寻真正的电脑知识 原作者所有 转载请注明出处
发表评论
最新评论
- 引用 ydjj
- 本帖最后由 ydjj 于 2017-8-10 21:19 编辑
感谢R大的辛苦评测~
超频后渲染16打10还打不过?这我还真的没想到
等x264和265的avx512优化上来了差距不更大?
- 引用 royalk
ydjj 发表于 2017-8-10 21:16
感谢R大的辛苦评测~
超频后渲染16打10还打不过?这我还真的没想到
等x264和265的avx512优化上来了差距不更 ...
渲染没问题,编解码打不过,但我总觉得编解码的优化还不到位,不知道是BIOS问题还是系统问题。
 专业回收各类测试平台
专业回收各类测试平台- 引用 Mufasa
royalk 发表于 2017-8-10 21:22
渲染没问题,编解码打不过,但我总觉得编解码的优化还不到位,不知道是BIOS问题还是系统问题。
...
视频解码那个,是软件的问题,等软件厂商优化就好了。
我用双路E5的16C32T系统,也发现,看视频时,只满载一颗CPU,另一颗打酱油。
- 引用 ydjj
royalk 发表于 2017-8-10 21:22
渲染没问题,编解码打不过,但我总觉得编解码的优化还不到位,不知道是BIOS问题还是系统问题。
...
渲染算了下也有问题
比如blender那个
16核4G vs 10核4.6G
换算下来,核心x频率增加了39%,但成绩只是好了13.35%……
- 引用 royalk
ydjj 发表于 2017-8-10 21:48
渲染算了下也有问题
比如blender那个
16核4G vs 10核4.6G
blender那个十几秒就完了,估计线程draw call耗时占比例过大,如果跑时间长一点的这个差距应该会趋于正常。
 能不能来一发Linux测试?
能不能来一发Linux测试?- 引用 xyj1232007
- 最后那张图……脸盆U

- 引用 aibo
- 本帖最后由 aibo 于 2017-8-11 00:03 编辑
这次的线程撕裂者就是2个节点的NUMA。
正常模式的延迟是惨不忍睹的,特别是内存频率低的时候。
开NUMA的local模式的话,游戏方面就类似ryzen了。不过这时候多核心的优势就会缩小很多。
anandtech的评测很明显的反应了这个特征。
另外,legacy模式是关掉HT,不是关掉一个die
- 引用 lovelesski
- 家用估计用不上了,土豪上。
- 引用 ydjj
royalk 发表于 2017-8-10 21:53
blender那个十几秒就完了,估计线程draw call耗时占比例过大,如果跑时间长一点的这个差距应该会趋于正常 ...
仔细拜读了全文后
我觉得12核的7920x只要能超到个4.3~4.5G,打1950x一点都不虚

- 引用 haomingci3
- 本帖最后由 haomingci3 于 2017-8-11 07:12 编辑
建议之后的测试里面加入R15能耗比对比,现在很多评测有个问题,贴AVX2甚至是AVX512的功耗,但是测试里面没有AVX2和AVX512应用,或是只提及一个,让人误以为测试得到的功耗是全部或者多数测试项目的运行功耗。
R15是纯SSE应用,也刚好符合了一些AVX无用党的胃口,并且实际上有AVX offset这种设定,按照xeon的玩法,用的到AVX2/AVX512的时候使用低频即可获得超越高频SSE/AVX1的性能。
根据一些有R15能耗比和其他一些区分指令集的测试看,R15(SSE浮点)同频同核数是KBL占优,AVX1是ryzen占优,AVX2是KBL占优。比较理想的测试是SSE,AVX1,AVX2,AVX512找到分别的典型应用测试分数和功耗进行对应。
本人拙见,仅供参考
- 引用 xiaokey
- AMD Ryzen ThreadRipper 1950X与技嘉X399 AORUS Gaming 7评测
多媒体处理与创作类软件效能测试
Blender 2.78c“ Ryzen TR 1950X也是核心多干活快,默频就已经超过了7950X的4.6G成绩。”
是不是写错了
没有用7950X啊 是7900X
我不是找茬的 我是提醒你一下
最后感谢R大一直带着我们玩超频
热门评论
热门评论

